-
 Multiple regressions on one dataset?
Multiple regressions on one dataset?
I'm not sure if I'm phrasing this question correctly, but here goes:
My theory behind modeling to beat the spread has always been to use the historical accuracy of Vegas lines against them. As many are probably aware, point spread vs favorite winning percentage for college football/basketball and NFL/NBA are very accurately estimated via logarithmic or power regression. However, on the lower (50-55% win percentage) and higher (large point spreads) ends, these regressions break down to a degree. Essentially, this means the regression is only accurate on "average" games -- meaning not close games, and not against big spreads.
However, what if you were to break down your regression into say 3 parts? Is this valid, either statistically or analytically? Would this constitute overfitting? If I model a game using a power y=C*X^B equation for win percentages over say 55%, but a linear fit y=mx + b for games of 50-55% win percentage (and, of course, a third percentage to model the high end)... would this make sense? I've never really considered it before, but I have a model that works pretty accurately in a lot of games, but really blows it in the close ones. Just curious if anyone has any insight.
Thanks
-
I think that is a pretty good idea overall. People break down complex relationships into linear approximations all the time. I am an engineer and we do this a lot at various portions of a curve for example. Sounds like you are doing the same thing. Best thing to do is just test it on out of sample data. Good luck.
-
-
 SBR PRO
SBR PRO
regressions can have multiple inputs (X) and a single output (Y). I'm not sure if this is what you are referring to in regards to 3 parts. When you perform the regression you can view the "t" and "p" values to find which are the most relevant.
-

Originally Posted by
a4u2fear

regressions can have multiple inputs (X) and a single output (Y). I'm not sure if this is what you are referring to in regards to 3 parts. When you perform the regression you can view the "t" and "p" values to find which are the most relevant.
More like something like this:
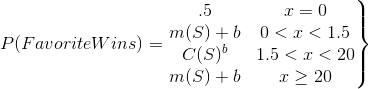
Except with favorite winning percentage as the independent variable, and point spread as the dependent variable. Essentially, solving all those equations for S. Follow me?
Note: those domains are just arbitrary. Just for the example.
-
I follow you. I don't see any problem with doing this, in principle.

 Reply With Quote
Reply With Quote